【C++并发编程】内存模型
引言
并发编程会涉及到底层的处理器架构和指令操作,并不是单纯的上层编程就能够实现的。在C++11之前,利用C++进行并发编程,需要依赖所在平台特定的编程规范,程序的复杂度和移植性是很大的问题。C++11标准之后,以标准库组件形式提供对并发机制的支持。而这些组件均依赖于内存模型的语言保证。
简单的讲,内存模型的作用就是在任意硬件环境下,当然包括多核处理器的多级缓存结构,保证对内存的访问符合用户需求和预期。
现代CPU缓存结构
在讲内存模型前,有必要讲一下现代CPU的缓存结构,这能有效的说明内存模型为何是保证并发编程的基础。
现代的CPU的处理速度非常快,即使是普通PC上的处理器也能轻松达到每秒执行$10^9$数量级的指令。为了解决处理器和物理内存之间巨大的响应差距,人们引入Cache(高速缓存),通常需要多级缓存才能使得处理器和主存之间能高效的传输数据。而随着后摩尔定律时代的到来,单核处理器已经无法得到巨大提升,人们开始退出多核处理器,来进一步提升计算机整体性能。多核处理器带来许多好处,但它同样需要使用缓存,这种情况会造成许多单核处理器下没有的并发编程难题。我们先看一下多核处理器的结的。
以一个四核处理器为例:
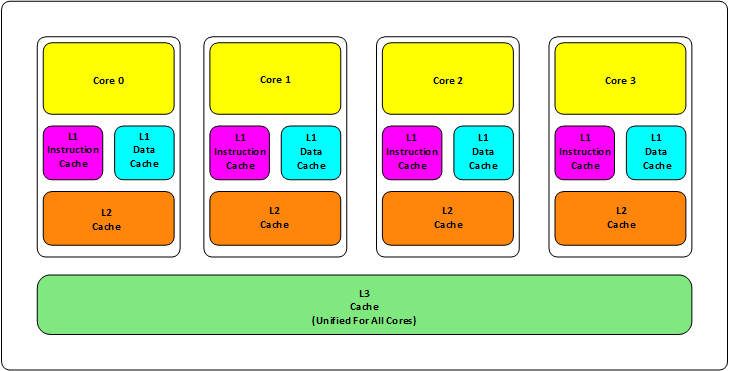
现代处理器一般都是三级缓存结构:
- L1 缓存。每个核有两个,包括L1数据缓存和L1指令缓存。大小一般在几十到几百KB,我的Intel Core i5-10400F处理器是384KB。速度一般在几个CPU时钟周期;
- L2 缓存。每个核有一个L2缓存。大小一般在几百KB到几MB,我的Intel Core i5-10400F处理器是1.5MB。速度在10多个时钟周期;
- L3 缓存。多个核心共享一个L3缓存。大小在几MB到十多MB我的Intel Core i5-10400F处理器是12MB。速度在几十个时钟周期;
可以想象,在这样一个多核多级缓存结构下,如果核0、核1都从同一内存中读取了一个值,例如x。当核0更新了x,为了保证高速,x更新后也保存在核0的专属缓存上(L1或L2),那么当核1也想更新x的时候该怎么做呢,甚至核2如果想读取x,该从哪儿读呢,主存上的值已经不是最新值,最新值在核0的缓存上。所以我们需要一种规范或者合约,使大多数程序员不需要考虑这么多硬件细节也能写出符合他们预期的程序。
内存模型
内存区域
现在,我们在看一个问题,先还不考虑共享数据这种显而易见的问题。看个更惊悚的:
char b = 0;
char c = 0;
// thread 1
void f() {
c = 1;
int x = c;
}
// thread 2
void g() {
b = 1;
int y = b;
}
这样的情况下,两个线程分别处理b和c,有什么问题吗?能保证最后x == 1, y == 1吗?
这好像没有什么数据竞争,线程之间没有什么影响,实际上仍然可能发生数据竞争,例如考虑这样的顺序:
c = 1;
b = 1;
y = b;
x = c;
如果没有一个内存模型作为保证,很可能b和c在同一个内存区域,处理器更新c的时候会覆盖b,更新b的时候会覆盖c,所以上面的执行顺序就会造成c先更新为1,但是后面更新b的时候又把c给覆盖了,造成c变为0,最后x为0的奇怪结果。
也就是说,有了C++内存模型才能保证两个更新和访问不同内存区域的线程可以互不影响地执行。因此,并发编程只需保证全局共享变量位于不同内存区域就可以避免线程间相互影响(char是基本类型,保证在不同内存区域)。
指令重排
还有一个问题是,为了提高性能,编译器、优化器和硬件都可能重排指令顺序,考虑下面的代码:
int x;
bool x_init;
// thread 1
void init() {
x = initialize();
x_init = true;
}
x 和 x_init看似没啥关系,很可能被重排为:
x_init = true;
x = initialize();
这好像没有什么问题,直到你发现有另一个线程在等待x被初始化好:
// thread 2
void f2() {
int y;
while (!x_init) {
this_thread::sleep_for(milliseconds(10));
}
y = x;
}
如果被重排了,y可能被一个还没有初始化的x赋值,这显然违反了我们的本意。对此,C++内存模型提供保证指令不被重排的方式(也就是原子变量)。
内存序
上面说到的指令重排以及防止指令重排都是针对某一线程的某一代码段的执行次序而言的。在多线程之间,关于指令(代码)的执行次序,C++内存模型对此有着更为复杂的保证。我们把这种保证叫做内存序或者内存次序。
顺序一致性
顺序一致性(memory_order_seq_cst)是最简单的内存序。这也是原子变量默认内存序。考虑下面代码:
char b = 0;
char c = 0;
// thread 1
void f() {
c = 1;
int x = c;
}
// thread 2
void g() {
b = 1;
int y = b;
}
由于是顺序一致性内存模型,则执行顺序可能是下面几种(都满足顺序一致性,即不同线程观察到的内存区域的值在同一时刻都是一样的):
// 1
c = 1;
x = b;
b = 1;
y = c;
// 2
c = 1;
b = 1;
x = b;
y = c;
// 3
b = 1;
y = c;
c = 1;
x = b;
因此,最终结果x和y至少有一个1,不可能都为0。
更宽松的内存序
在有的场景下,并发程序之间并不需要顺序一致性这么严格的内存序就可以保证程序的正确性。这时,采用更宽松的内存序可以获得显著的性能提升。在无锁编程(不显示使用锁的并发程序技术)中,原子变量内存序可以从默认的顺序一致性改为memory_order_acquire或memory_order_release,依然能够达到想要的次序,同时大大提升了并发性能。
更宽松的内存序为memory_order_relaxed,考虑下面代码:
// thread 1
r1 = y.load(memory_order_relaxed);
x.store(r1, memory_order_relaxed);
// thread 2
r2 = x.load(memory_order_relaxed);
y.store(42, memory_order_relaxed);
代码可能会有时光倒流的次序效果:
y.store(42, memory_order_relaxed);
r1 = y.load(memory_order_relaxed);
x.store(r1, memory_order_relaxed);
r2 = x.load(memory_order_relaxed);
这产生r2 == 42这样不可思议的结果,这种宽松的内存序看似没有用,但是在系统内核、虚拟机上能带来显著提升。